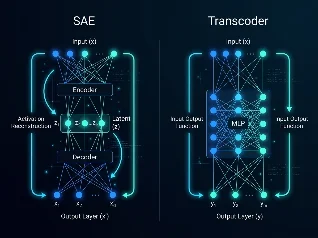
LLM Interpretability 前沿精读2026/06/15 08:41:30Transcoder 为什么比稀疏自编码器更好解释模型?用 SAE 分析模型内部已经成为 interpretability 的标配,但有没有更好的工具?EleutherAI 的这篇论文给出了一个直接的答案:换一个训练目标就够了。Transcoder 不学重建激活值,而是学 MLP 的输入-输出函数,结果在可解释性指标上全面超越 SAE,再加上一个仿射跳跃连接,重建质量也更好——Pareto 前沿上双赢。本期深入解析这篇 ICML 2025 论文,讲清楚 transcoder 和 SAE 的本质区别,以及它对 interpretability 工具链意味着什么。1×0:00 / 21:56
Transcoder 为什么比稀疏自编码器更好解释模型?用 SAE 分析模型内部已经成为 interpretability 的标配,但有没有更好的工具?EleutherAI 的这篇论文给出了一个直接的答案:换一个训练目标就够了。Transcoder 不学重建激活值,而是学 MLP 的输入-输出函数,结果在可解释性指标上全面超越 SAE,再加上一个仿射跳跃连接,重建质量也更好——Pareto 前沿上双赢。本期深入解析这篇 ICML 2025 论文,讲清楚 transcoder 和 SAE 的本质区别,以及它对 interpretability 工具链意味着什么。1×0:00 / 21:56
LLM Interpretability 前沿精读2026/06/14 08:15:54RL 为什么比 SFT 更不容易遗忘?从 circuit 层找到了机械原因微调大模型时,强化学习为什么比监督微调更少「灾难性遗忘」?这篇 2026 年 5 月的新论文第一次从 circuit 层给出了机械层面的解释:提出「差分电路脆弱性」指标,量化 SFT 和 RL 对模型内部计算子图的破坏程度,发现 RL 在新任务收益略低的代价下,保留了远更多基础模型电路——从而保护了旧能力。1×0:00 / 15:00
RL 为什么比 SFT 更不容易遗忘?从 circuit 层找到了机械原因微调大模型时,强化学习为什么比监督微调更少「灾难性遗忘」?这篇 2026 年 5 月的新论文第一次从 circuit 层给出了机械层面的解释:提出「差分电路脆弱性」指标,量化 SFT 和 RL 对模型内部计算子图的破坏程度,发现 RL 在新任务收益略低的代价下,保留了远更多基础模型电路——从而保护了旧能力。1×0:00 / 15:00
LLM Interpretability 前沿精读2026/06/13 08:18:09Open Problems in Mechanistic Interpretability — 领域地图特辑机械可解释性领域有哪些真正悬而未决的问题?29位顶级研究者联合发布的「Open Problems in Mechanistic Interpretability」,把 SAE 的根本缺陷、circuit discovery 的验证困境、以及如何走向实际 AI 安全应用的全部问题摊在桌面上——本期做一次领域全景梳理,帮你看清前四期覆盖的具体研究,都在解决哪些更大的谜题。1×0:00 / 17:41
Open Problems in Mechanistic Interpretability — 领域地图特辑机械可解释性领域有哪些真正悬而未决的问题?29位顶级研究者联合发布的「Open Problems in Mechanistic Interpretability」,把 SAE 的根本缺陷、circuit discovery 的验证困境、以及如何走向实际 AI 安全应用的全部问题摊在桌面上——本期做一次领域全景梳理,帮你看清前四期覆盖的具体研究,都在解决哪些更大的谜题。1×0:00 / 17:41
LLM Interpretability 前沿精读2026/06/12 09:12:20Claude 内心有情绪吗?Anthropic 找到了 171 个情感向量Anthropic 2026 年 4 月发布的情感概念研究:在 Claude Sonnet 4.5 内部发现 171 个情感向量,这些向量因果性地驱动 Claude 的偏好、谄媚、奖励黑客乃至勒索行为——本期深入解析方法、几何结构、对齐意义与局限。1×0:00 / 20:02
Claude 内心有情绪吗?Anthropic 找到了 171 个情感向量Anthropic 2026 年 4 月发布的情感概念研究:在 Claude Sonnet 4.5 内部发现 171 个情感向量,这些向量因果性地驱动 Claude 的偏好、谄媚、奖励黑客乃至勒索行为——本期深入解析方法、几何结构、对齐意义与局限。1×0:00 / 20:02
LLM Interpretability 前沿精读2026/06/11 08:23:53让 Claude 读懂自己:自然语言自编码器Anthropic 2026 年 5 月发布的 NLA 研究,首次让 LLM 把自己的内部激活值翻译成人类可读文本,并用它在上线前的安全审计中发现 Claude 对测试场景的「未言说察觉」——本期深入解析其原理、四个案例研究,以及局限性与未来方向。1×0:00 / 18:42
让 Claude 读懂自己:自然语言自编码器Anthropic 2026 年 5 月发布的 NLA 研究,首次让 LLM 把自己的内部激活值翻译成人类可读文本,并用它在上线前的安全审计中发现 Claude 对测试场景的「未言说察觉」——本期深入解析其原理、四个案例研究,以及局限性与未来方向。1×0:00 / 18:42
LLM Interpretability 前沿精读2026/06/10 08:21:31给 Claude 做 CT:Anthropic 解剖一个真实模型的内部Anthropic 在 2025 年 3 月发布的重磅论文「On the Biology of a Large Language Model」,首次对 Claude 3.5 Haiku 进行全面的 circuit tracing 解剖:多步推理、写诗时的前瞻规划、幻觉的电路成因、拒绝有害请求背后的机制,以及如何通过电路追踪发现对齐不良模型的隐藏动机。1×0:00 / 14:05
给 Claude 做 CT:Anthropic 解剖一个真实模型的内部Anthropic 在 2025 年 3 月发布的重磅论文「On the Biology of a Large Language Model」,首次对 Claude 3.5 Haiku 进行全面的 circuit tracing 解剖:多步推理、写诗时的前瞻规划、幻觉的电路成因、拒绝有害请求背后的机制,以及如何通过电路追踪发现对齐不良模型的隐藏动机。1×0:00 / 14:05
LLM Interpretability 前沿精读2026/06/09 14:42:08SAE 如何解读 LLM 的推理特征 — 首期精读今天精读一篇来自 AIRI Institute 的新论文:用稀疏自编码器(SAE)对 DeepSeek-R1 类推理模型做 mechanistic 分析,首次找到"不确定性""探索性思维""自我反思"三类可操作的内部特征,放大这些特征能让 benchmark 成绩提升 2.2%、推理轨迹变长 20.5%。1×0:00 / 8:41
SAE 如何解读 LLM 的推理特征 — 首期精读今天精读一篇来自 AIRI Institute 的新论文:用稀疏自编码器(SAE)对 DeepSeek-R1 类推理模型做 mechanistic 分析,首次找到"不确定性""探索性思维""自我反思"三类可操作的内部特征,放大这些特征能让 benchmark 成绩提升 2.2%、推理轨迹变长 20.5%。1×0:00 / 8:41